蒸馏学习妙用:Learn From Blackbox Models
前言
近期需要训练一个对话系统中的情绪识别模型,但苦于没有训练集,恰逢之前某位兄台有提到过蒸馏学习,故灵光初现,借助百度提供的对话情绪识别接口和一部分无标注的数据,抽取一些蒸馏训练集,以此来高仿一个情绪识别模型为己用。
蒸馏学习概述
蒸馏学习并非一种全新的深度学习网络,只是一种简化模型的思想,可以解决这样一件事情:一个训练好的复杂深度网络在实际工程生产中扮演预测模型的角色,但是由于模型的复杂特性导致了实际资源消耗较大,并且预测效率较低。知识蒸馏(Knowledge Distillation)是 Hinton 大神在 2015 年提出的黑科技[1],其基本思想就是借助一个小规模的模型来学习大规模复杂模型中的中间结果(一般取输出层激活前的目标值)。
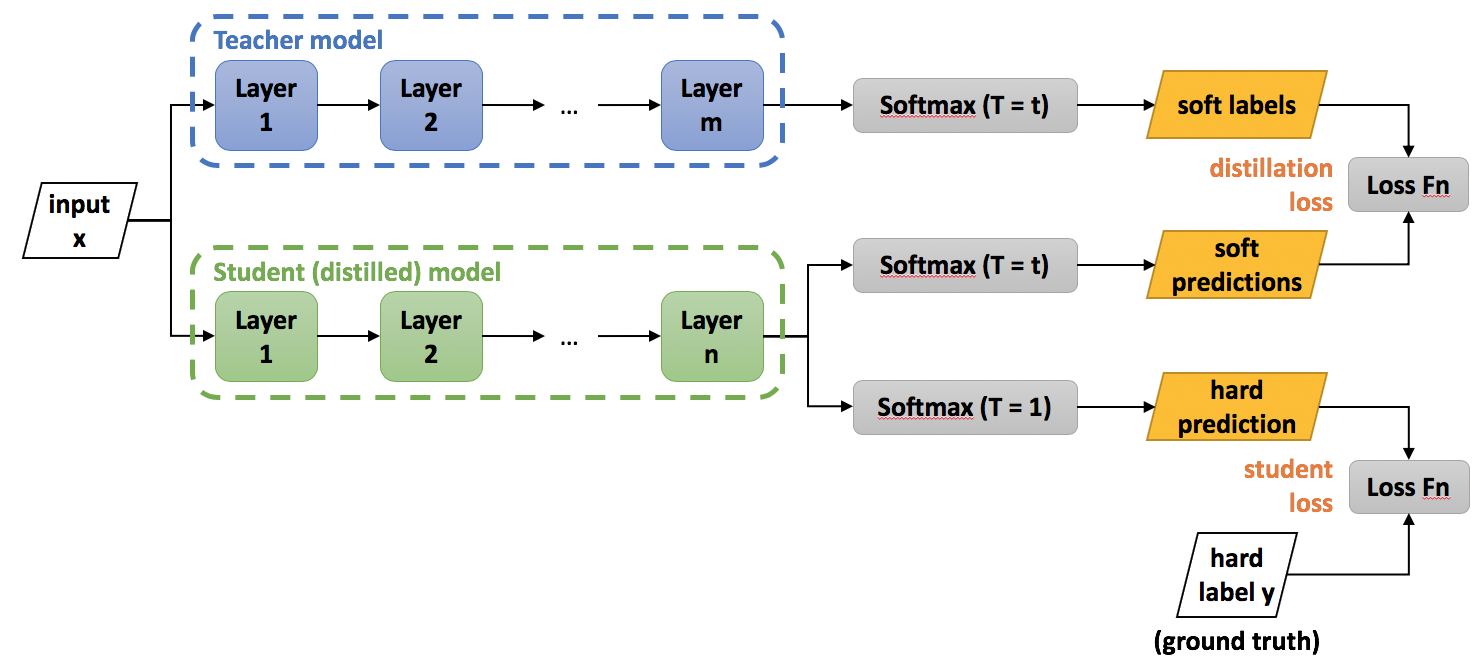
一般情况下,我们做模型的蒸馏是为了用小规模的简单模型来替换大规模的复杂模型,我们依然还是拥有一部分标注好的训练集的,我们取蒸馏过程的loss的时候,可以将 softloss和 hardloss加权,来保持我们的训练目标既能够朝向正确的目标,又能学习到大模型的预测中间结果。
\[Total\_Loss = SoftLoss(y, \hat{y}_{soft}) + \lambda * HardLoss(y, \hat{y})\]其中 SoftLoss 的target也是一个概率分布,转化成衡量两个分布之间的差异,因此退化为 KL-divergence。而 HardLoss 则依然保持为 CrossEntropyLoss.
在计算 SoftLoss 的过程中,我们需要增加温度限制来将输入做一些概率平滑,让预测目标值之间的概率差异小一些。
\[y_i^{soft} = \frac{\exp{(x_i/T)}}{\sum_j \exp{(x_j/T)}}\]经验温度取 10-20 之间。
蒸馏黑盒模型
跟模型压缩任务中的蒸馏过程不同,我们如果要对一个黑盒模型做蒸馏,是无法直接获取到其中间结果的,不过如果黑盒模型可以输出一个置信度或者最终的概率分布,则完全可以反推出我们想要的 SoftTarget。公式很简单,就不用推导了。
\[p_i^{soft} = softmax(\frac{\log p_i}{T})\]其中, \(p_i\) 表示我们黑盒模型获取的输出,\(T\) 表示温度。
此外,蒸馏过程还需要 Hard Target,这确实是一个比较困难的地方,我们要自己做一批数据标注,可能非常困难,因此我们忽略 Hard Target,只用 Soft Target 来测试看看是否能够获取到我们希望得到的结果。
实践
百度AI开放平台提供了对话情绪分析的接口[[3]],能够输出乐观、中性、悲观三种情绪的概率分布预测,这让我们的工作得以事半功倍。另外幸运的是,我们有一款线上的产品可以获取到未标注的用户对话,因此我们随机抽取了10w+规模的无标注数据来从百度的情绪分析获取我们想要的 SoftTarget。
我们用来模拟百度情绪分析的模型用了 BERT + 单向 GRU 来提取特征,将两部分特征 Concat 起来,上层加上2层的 Highway 作为输出。
关于 Loss,我们尝试了 KL-Divergence 和 MSELoss。发现通过MSELoss 更容易收敛,并且最终效果也更好一些。以百度输出的结果为Target,最终predict的准确率可以达到97%+。