[译]任务型对话系统的用户模拟模型 [USER MODELING FOR TASK ORIENTED DIALOGUES]
本文理解自 USER MODELING FOR TASK ORIENTED DIALOGUES
译者注:本文作者阵容相当强大,来自 UCSB,Google AI, Amazon Alexa AI, Uber AI Labs, Facebook Conversational AI。
原文摘要
本文介绍了一个端到端神经网络模型,用于模拟面向任务的对话系统中的用户。对话系统中的用户模拟重点在于以下两个方向:(i)自动评估不同的对话模型(ii)训练任务型的对话系统。我们设计了一个层次化 Seq2Seq 模型,它首先使用递归神经网络(RNN)将初始用户目标编码并且转换为固定长度的向量。然后使用另一个 RNN 层对对话历史状态信息进行编码。在每一轮对话中,用户的回复从对话层的 RNN 的隐藏表示中解码生成。层次化用户模拟器(HUS)方法能够让模型捕获到用户意图的隐藏信息,不需要显式的对话状态跟踪过程。我们进一步开发了若干变体模型,利用了隐含变量模型,将随机波动引入了用户的回复中,以提升模拟用户回复的多样性,以及一个目标正则化机制用于惩罚用户响应与初始用户目标的差异。我们通过将每个用户模拟器与用不同目标和用户训练的各种对话系统策略进行交互来评估电影票预订领域中的模型。
1. 概述
面向任务的对话系统旨在通过用自然语言与用户进行交互来帮助用户实现目标。以前关于面向任务的对话系统的工作可以分类到两个大的主题:(i)具有模块化连接组件的流水线架构,这些组件是独立训练的[1,2,3等],以及(ii)端到端架构,其中组件可以联合训练[4,5,6,7等]。端到端训练方法的主要目的在于防止通过组件流水线方法的模块间误差的传递,以及在有新的数据可用时能够进行持续训练,即使有些组件还没有完全获取标注结果。端到端训练方法也被证明可以带来更高的任务成功率和更短的对话长度[7等]。通常,这些模型使用来自各种来源的带标注的对话进行训练,包括通过各种群体实验扩充的模拟对话的数据。
最近,有一些文章提出了用于对话系统的序列到序列(seq2seq)用户模拟器的方法,用于使用强化学习[8,9,10等]来训练对话策略模型的过程。尽管这些模拟器可以产生成功的对话,但它们需要有标注的对话状态,并且缺乏必要的机制来产生多样化的响应,这限制了它们评估不同对话系统的能力。
除了训练端到端对话系统外,建模用户行为还有其他的例子。 Google Duplex demo1(谷歌全双工) 是模仿人类完成某些任务的一个很好的例子。此外,这些模拟器可用于评估面向任务的对话系统的各种替代方法。大多数系统都是在固定测试语料库上进行评估,这是一种能够测试系统是否可以准确地与各种不同的用户进行交互但却很局限的方法。评估面向任务的对话系统的另一种方法是使用众包,可以更准确地得到成功的用户交互。但是,其昂贵且耗时的特点仅允许生成有限的对话集。此外,面向任务的对话系统具有各种模型决策,这些决策在使用众包时是不可行的。一个可以在相似的对话启动中横向比较多个系统的可扩展且准确的评判标准,将对于改善上述瓶颈至关重要。
在本文中,我们提出了几种端到端用户模拟模型,旨在模拟真实和多样化的用户行为。我们的用户模拟器的一个目标是,在给定的一组用户目标和对话场景中的对话系统或其组件实现横向比较。我们的方法还有另一个目标,就是通过使用多样性的交互数据,借助监督和强化学习来训练对话策略。
受最近的对话模型[11]的启发,我们开发了一个层次化的seq2seq用户模拟器(HUS),它隐式地跟踪多轮对话中的用户目标。 HUS首先对用户目标和对话历史中观察到的每轮 system turn 编码为向量表示。然后从用户目标向量初始化,使用更高一层的 encoder 在每个 timestamp 用system turn 向量作为当前输入来生成对话历史表示。最后,从该对话历史表示中解码模拟的用户对话轮次。
虽然HUS可以生成成功的对话,但是在给定相同的用户目标和系统回复的情况下,它将始终生成相同的模拟用户对话轮次。为了让对话的变化更类似人类并生成更丰富的用户对话过程,我们提出了一个新的变量框架(VHUS),可以将未观察到的潜在变量引入用户对话过程。此外,对于HUS,用户的轮次和用户目标仅和用户轮解码器相关,导致在整个交互过程中重复先前指定的信息。我们在最终的损失函数中引入了一种新的目标正则化方法,旨在最大化生成的用户轮次和真实的用户目标之间的词重叠率。用户模拟器将在对话行为级别工作,并以用户行为和相关的槽位-取值对的形式生成用户回复(示例对话如图1所示)。最终,我们使用了基于模板的自然语言生成方法将最终输出转换为自然语言。
用户目标: date=Friday, num tickets=2, theatre name=DontCare, movie=Sully, time=DontCare
0
SYSTEM: Hi, how can I help you?
greeting()USER: Hi, I’d like to buy tickets to see the Sully movie.
greeting() intent(buy movie tickets) inform(movie=Sully)
1
SYSTEM: You wanna see Sully. How many tickets would you need?
confirm(movie=Sully) request(num tickets)USER: 2 tickets please.
inform(num tickets=2)…
我们通过将每个用户模拟器与经过不同目标和架构训练的多个系统策略进行交互来评估电影票预订领域中的模型。实验表明,基于强化学习的策略对于用户行为的随机变化更加鲁棒,而监督模型的准确性会大幅下降。我们的目标正则化方法在所有系统策略中产生明显更短的对话(即避免围绕用户或系统误解),并显示更高的任务完成率。最后,人类评估显示,在所有涉及到方法中,本方法具有最高的自然度分数。
2. 与本文相近的工作
我们工作中提出的模型体系结构受到[12,11,13]中研究的层次化深度学习模型的启发,这些模型在对话生成任务上的表现也优于普通的seq2seq和语言模型。诸如变分自动编码器之类的变分方法用于无监督或半监督模型训练[14,15],帮助我们提升了最终性能指标以及所生成输出的多样性。
在任务型对话模型训练中,已经有工作研究了基于议程的用户模拟[16]。使用线性模型[17,18]以及隐马尔可夫模型[19]的监督学习方法也被提出用于模拟用户。最近,seq2seq神经网络模型被提出用于用户模拟[8,9,20等],其利用额外的状态跟踪信息并且对话轮次的编码更加粗略。 Kreyssig等[20]的工作进一步表明,在每轮对话中具有状态跟踪信号的普通seq2seq模型可以在几个指标(包括成功率)上胜过基于议程的用户模拟器。另一项使用seq2seq模型进行用户模拟的工作是[10],将seq2seq模型与基于语言建模的方法进行比较,以自然语言生成用户的回复。它们使用两个独立的编码器对上下文(先前的用户轮次)和当前系统轮次进行编码,并输出连接之后的向量。然后从该最终借助解码得到用户轮次的向量。我们提出了一种端到端的层次化seq2seq方法,该方法可以编码整个对话历史而无需任何特征提取,也不需要任何带标注的外部状态跟踪。更进一步,我们使用非均匀抽样方法和目标正则化引入了几种新的变体,这些变体结构改进了对话度量过程,并允许与不同的系统策略进行更彻底的比较。
3. 问题描述
根据端到端监督对话模型的最新进展,我们考虑一个逆向问题,在给定用户目标 C 和系统回复轮次 S1,S2,···,St 的历史的条件下生成用户轮次 Ut。用户目标是一组槽值对(例如时间:12pm)以及预定义的用户个性(例如,积极的,合作的),用户个性用于在生成用户回复轮次时决定采样分布。类似地,系统和用户回复也是一组动作来表示,其中每个动作具有对话动作类型(例如inform)和一组相应的槽位 - 值对,例如 inform(time= 12pm,theatre=”AMC Theatre”)。
我们首先通过用以下值之一替换每个槽位的值来生成每个输入的更粗略的表示:{Requested,DontCare,ValueInGoal,ValueContradictsGoal,Other}。如果系统请求槽位的值,我们将这些槽位值替换为 Requested。如果槽位的值出现在用户目标中或与用户目标相矛盾,我们将分别用 ValueInGoal 或 ValueContradictsGoal 替换这些值。如果用户目标中的槽的值是灵活的,意味着用户可以接受任何提供的值,我们在每个输入中用DontCare替换相应槽的值。最后,我们用Other替换其他值。在测试期间,基于这些粗略值,我们从用户目标,系统转向或知识库中抽样实际值。受到最近结构化数据方法成功的启发,我们接下来根据[21]所述的方法线性化每个输入(用户场景,系统和用户回复)以生成词汇序列。例如,我们用 ValueInGoal 替换图1系统Turn-1中的实际电影名称Sully,并将动作序列转换为一系列标记,如“confirm”,“(”,“movie = ValueInGoal”,“)” ,“request”,“(”“num tickets”,“)”。
我们现在更正式地描述我们的问题。给定用户目标序列 C 和每个回合中的系统回复序列 St 历史,我们的任务是生成一个新的词汇序列,该序列与正确的用户回复序列 Ut = {ut1,ut2,···,utNU} 轮流相匹配。在这里,一轮成功的用户回复可能需要混合来自用户目标的信息,以及系统和用户回复的历史。此外,我们并没有假设给出了用于对话状态跟踪的监督信息。
4. 用户模拟用户的层次化 Seq2Seq 模型
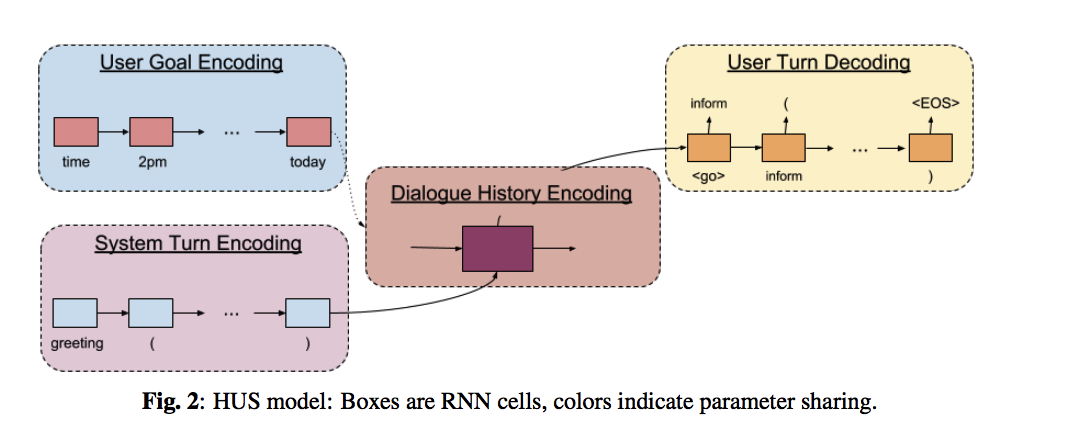
我们现在在图2中展示我们的监督模型,并在完全端到端的设定中描述它们的操作。 我们的基线模型是一个层次化的 seq2seq 神经网络,可以在单个系统和用户回复以及整个对话级别上运行。 给定(C,St,Ut)三元组,模型首先对用户目标 C 和系统在第 t 轮的回复对话(St)进行编码,所用的方法为解耦的递归神经网络(RNN)并行的向量空间表示。 我们用另一个 RNN 从用户目标的向量化表示初始化,并在第 t 轮将系统回复的向量化表示序列再次编码成隐藏向量。 最后,使用RNN序列解码器从该隐藏向量解码对话动作中的模拟用户响应和第t轮回复(Ut)处的参数。 接下来我们讨论该模型的缺点,并提出几种模型改进,这些改进在一定意义上属于非监督的,因为其并不需要额外的监督数据。
4.1. 记号说明
每个词汇 w 来自词汇表 V 并且与向量 \(e_w\) 相关联。 \(E^C\),\(E^{S_t}\) 和 \(E^{U_t}\) 分别表示用户目标,系统和用户在第t轮回复的词汇嵌入向量序列。 我们的模型利用RNN编码器和解码器的功能,所用的 RNN 单元为 GRU 单元[22]。 我们将基于轮次的 RNN 编码器的隐藏状态的均值称为序列的编码。
4.2. 层次化 Seq2Seq 用户模拟(HUS)
我们模型的核心是一个层次化的seq2seq神经网络,它首先对用户目标和系统回复进行编码,并从对话级别表示生成用户回复。
编码用户场景和系统 使用RNN(Enc),我们将用户目标编码为
\[\tag{1} h^C = Enc(e^C; \theta_C )\]其中,\(h^C\) 表示编码向量,\(\theta_C\) 表示用户目标编码器的参数。我们用另一个 RNN 来对系统的回复轮次进行编码:
\[\tag{2} h^S_i = Enc(e^{S_i}; θ_S)\]其中,\(h^S_i\) 表示编码向量,\(\theta_S\) 表示系统回复编码器的参数。\(\theta_S\) 在每个系统轮次编码器中是共享的,并且和 \(\theta_C\) 完全解耦。
编码对话历史 上一步对每一轮的系统回复都做了编码,在完整的对话轮次中,我们就有了一个系统回复编码的序列,\(h^S_0 , h^S_1 , · · · ,h^S_t\),我们使用了另一个 RNN 来基于用户目标的编码向量来编码整个对话的历史:
\[\tag{3} h^D_0 = h^C\] \[\tag{4} h^D_t = Enc(\{h^S_i\}_{i=1,··· ,t}; θ_D)\]其中 \(h^D_0\) 是初始隐藏状态,\(h^D_t\) 是对话历史编码,\(\theta_D\) 表示对话级RNN的参数。 理想情况下,对话级 RNN 能够跟踪用户目标并产生有意义的用户回复。
解码用户回复 给定第 t 轮的对话历史编码向量,我们用一个 RNN 解码器(Dec) 来生成用户对话轮次的词汇序列:
\[\tag{5} h^U_0 = h^D_t\] \[\tag{6} h^U_{t,i} = Dec(h^U_{t−1,i}; \omega_U )\] \[\tag{7} P(U^*_{t,i} = \omega_j ) \approx exp(e^T_j (W_U h^U_{t,i} + b_U ))\] \[\tag{8} U^*_{t,i} = argmax_{j} (P(U^*_{t,i} = \omega_j ))\]其中 \(h^U_0\) 是初始隐藏状态和 \(H^U_{t,i}\) 是第 t 轮和时间步长 i 时刻的隐藏向量。 \(U^*_t\) 是生成的用户回复词汇的序列。 \(W_U,b_U\) 和 \(\omega_U\) 是用户回复解码器的参数。 训练目标是最小化候选序列 \(U^*\) 和标准的用户轮次 \(U\) 之间的交叉熵误差。
结合对话长度 在训练期间,我们观察到不同用户性格的抽样可以随机产生更短或更长的对话,而HUS没有用到这一信息。 为了解决这个问题,我们在训练期间的每个轮次处将相应对话的长度附加到系统回复的编码中。 在测试的阶段中,我们从以下正态分布 N(5,2)中随机抽取对话长度。 对于后续章节,我们总是在模型中加入对话长度。
还有一个可替代的模型还将更明确地结合先前的用户回复,例如通过对用户回复编码和对用户回复编码的条件对话历史编码器进行编码; 但是我们没有观察到显着的收益 一个合理的原因是,用户回复是从对话历史编码中解码的,这些对话历史编码通过上一步的历史编码隐含地取决于上一步的用户回复。
4.3. 可变的 HUS
在给定相同的用户目标和对话历史的情况下,HUS 模型将生成完全相同的用户轮次。 但是,为了探索系统策略的稳健性并为不同类型的用户建模,我们需要一个能够生成更多样化且同时有意义的用户回复的模型。 在这里,我们提出了一种新的可变的层次化seq2seq用户模拟器(VHUS),其中未观察到的隐藏随机变量生成用户回复序列(图3)。 编码器与HUS完全相同,但隐藏状态 \(h^D_t\) 不直接传递给解码器。而是首先与从具有对角协方差矩阵的高斯分布生成的隐向量连接,然后传递给解码器。
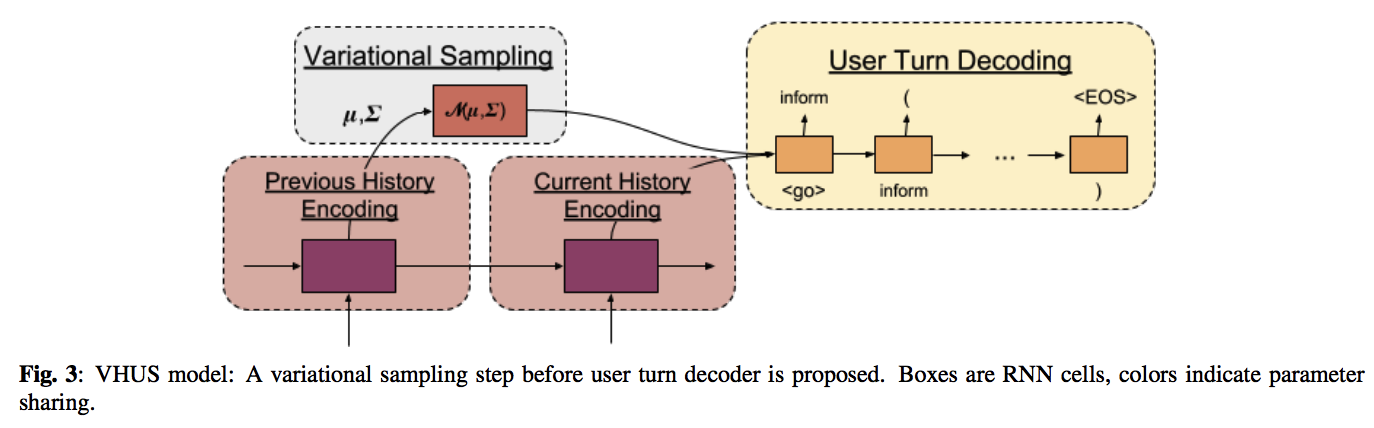
更正式地描述,给定对话表示序列 \(h^D_0,h^D_1,...,h^D_t\),我们使用先前的对话历史学习先验高斯分布 \(N(z \|\mu_x, \Sigma_x)\) :均值和协方差估计为如下
\[\tag{9} \mu_x = W_{\mu} h^D_{t−1} + b_{\mu}\] \[\tag{10} \Sigma_x = W_{\Sigma} h^D_{t−1} + b_{\Sigma}\]其中 \(W_{\mu},W_{\Sigma},b_{\mu}\) 和 \(b_{\Sigma}\) 是先验分布的新参数。 然后用单个向量 \(\hat{h}^D_t = FC([h^D_t; z_x])\) 初始化解码器,其中[.]是向量连接,FC是单层神经网络,并且 \(z_x\) 从先验分布中采样,\(z_x \sim N (z \|\mu_x, \Sigma_x)\) 。 我们还使用当前的对话历史来学习后验高斯分布:
\[\tag{11} \mu_y = \tilde{W}_{\mu} h^D_t + \tilde{b}_{\mu}\] \[\tag{12} \Sigma_y = \tilde{W}_{\Sigma} h^D_t + \tilde{b}_{\Sigma}\]其中 \(\tilde{W}_{\mu},\tilde{W}_{\Sigma},\tilde{b}_{\mu}\) 和 \(\tilde{b}_{\Sigma}\) 是后验分布的新参数。 我们在最终的交叉熵损失中加上了经过训练的先验和后验分布之间的Kullback-Leibler散度,比如:
\[L_{var} = \alpha KL(N (z|\mu_x, \Sigma_x)|N (z|\mu_y, \Sigma_y)),\]其中 \(\alpha\) 是两部分不同损失的权衡参数。
Our main intuition is that, when the decoder is conditioned on a noisy history, it will generate a slightly different user turn. By penalizing the KL divergence between prior and posterior distributions, we control the level of noise by ensuring that the previous and current histories are consistent.
我们的主要直觉是,当解码器以有噪声的对话状态历史为条件时,它将产生略微不同的用户回复。 通过惩罚先前和后验分布之间的 KL 分歧,我们可以一定程度上确保先前和当前历史是一致,以此来控制噪声的实际影响程度。
4.4. 目标正则化
HUS 和 VHUS 模型仅通过解码器的损失函数来学习用户回复和用户目标之间的关系,当用户变得偏离初始用户目标时,这可能产生相当长的对话。 在这里,我们引入了一种名为 VHUSReg 的新目标正则化方法来消除上述问题(图4)。 我们的基于轮次的编码器与 HUS 完全相同,但关于对话级RNN,我们并没有用用户目标表示来初始化,而是用零向量初始化它并更直接地调整用户目标上的解码器。 此外,我们惩罚对话级别的表示与用户目标之间的差异,以强制执行更直接的沟通。
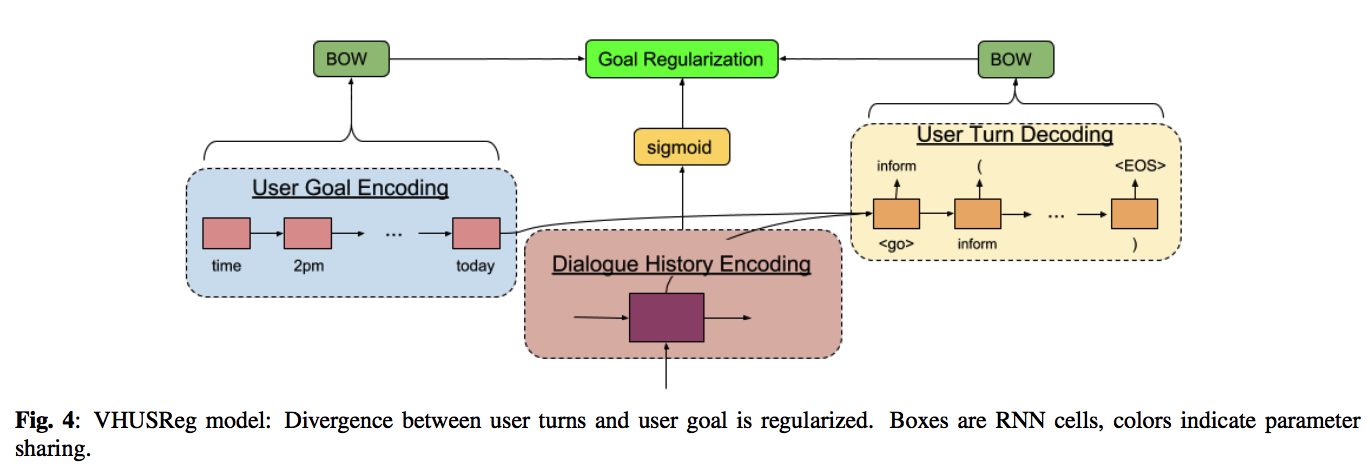
更正式的讲,给定系统回复编码的序列,我们可以生成对话的表示如下:
\[\tag{13} h^D_t = Enc({h^S_i }_{i=1,··· ,t}; \theta_D)\]其中编码器用零向量初始化。然后,我们生成一个新的对话表示如下:
\[\tag{14} \hat{h}^D_t = F C([h^D_t; h^C])\]其中,新的输出用用户目标和老版本的对话表示混合得到。类似的,我们用一个 RNN 解码器来从新的对话表示中生成用户回复的词汇序列。
为了控制用户回复和用户目标的差异,我们将用户回复和用户目标词汇序列之间的差异最小化,这取决于当前的系统回复。 我们首先生成当前用户回复和当前系统回复的词袋表示的近似值:
\[\tag{15} b^D_t = F C(h^D_t )\] \[\tag{16} b^S_t = F C(h^S_t )\]其中 FC 是具有 Sigmoid 激活函数的单层神经网络。 接下来,我们根据当前系统回复为当前用户回复建立一个新的词袋表示:
\[\tag{17} b^{\mu}_t = FC([h^D_t; h^S_t])\]接下来,我们引入了一个新的损失项,即保证每个词袋表示基本上准确,来最小化初始化用户目标和用户回复的词汇:
\[\tag{18} L_{reg} = ||b^{\mu}_t − BOW(C)|| + ||b^D_t − BOW(U_t)||+||b^S_t − BOW(S_t)||\]其中BOW(x)是为一组标记x输出词袋向量的函数,例如我们使用BOW(C)生成用于初始用户目标的词袋向量。 通过最小化每个词汇的词袋表示之间的差异,我们将用户目标和用户回复中的词汇对齐。
4.5. 带目标正则项的可变 HUS
最后,我们将各方法结合在一个混合框架中,将三个损失项相加起来形成最终的损失函数:
\[\tag{19} L = L_{crossent} + L_{var} + L_{reg}\]5. 实验结果和讨论
我们通过系统地将每个用户模拟器模型与两个不同的系统策略进行交互来呈现我们的实验结果,这些策略通过监督学习和强化学习进行。我们使用电影票务预订域中的数据集,并使用多个指标来评估和比较我们的模型,包括任务完成率[23]和对话长度。 我们使用基于模板的 NLG 来生成用户和系统动作序列的话语,我们借助众包为每个对话行为编写的一组模板库中采样模板,以及该程序可能用到的的参数集。
5.1. 系统策略模型
为了更好的对比,我们训练了两种先进的端到端系统策略模型:(1) 监督策略 (2) 强化学习策略。
监督策略 是一个可以学习将用户的自然语言回复转化为系统动作的端到端神经网络[7]。
强化学习策略 首先使用监督的策略模型进行初始化,并通过与基于议程的用户模拟器(不同于我们的模拟器)[7]进行交互来进一步微调,以探索和生成更多的训练数据。 使用 REINFORCE 算法[24]更新神经网络的参数。 在每个回合中给出一个小的负奖励(例如-1),并且在每个对话结束时,如果对话被成功终止,则给出大的积极奖励(例如20)。 从结果上来看,RL策略试图在实现高成功率的同时最小化对话长度。
这些策略使用自然语言话语作为输入并生成一系列系统动作,然后使用基于模板的生成将其转换为自然语言。 但是,用户模拟器仅利用系统回复的对话行为和参数。 在我们的用户模拟器中,我们还利用基于模板的 NLG 生成话语作为系统策略的输入,其中模板从从众包收集的模板集(约10000)中进行采样。 每个策略都在与我们不同的数据集上进行训练并修正。 为了保持公平的比较,我们首先随机生成1000个用户目标。 为了评估策略和模拟器,我们通过交互每个用户模拟器和策略对来生成所有用户目标的对话。
5.2. 数据集
我们使用面向任务的对话语料库[25]。 在每次对话开始时,随机生成用户目标,并使用具有有限状态机的对话代理和基于议程的用户模拟器来填充对话[16]。 每个对话还包含具有不同配合度和随机性设置的用户个性。 训练和测试数据集各有10,000个对话。 对话长度的最大数量设置为20,并且在每个轮次处最多有3个对话动作序列,最多5个槽位-值对。
5.3. 评价指标
我们使用三个指标来评估用户模拟器和系统策略之间的成功交互:精确目标匹配,部分目标匹配和对话长度。
- 如果系统在对话结束时确认的最终槽位-值对完全匹配用户的目标,则模拟对话具有精确的目标匹配(EM)得分1。
- 模拟对话的部分目标匹配(PM)得分是用户目标中所有可能槽位的集合上的正确槽位-值对的数量。
- 我们还提取了对话长度,每个对话的平均轮数(用户和系统),以评估不同设置(如噪声)的影响。
我们还利用两个回复多样性指标来测量用户回复的多样性和系统策略的稳健性:每个系统回复下的用户回复的对话行为的熵和困惑度。
5.4. 训练细节
我们使用大小为150的随机初始化词向量表示。我们将基于轮次层面的和基于对话层面RNN的隐藏状态大小设置为200.我们使用 Adam 优化方法[26]训练我们的模型,初始学习率为1e-3。 我们以 0.5 的概率应用Dropout并使用大小为32的 mini-batch。我们将模型迭代了10个 epoch 并通过开发集来选择最佳模型。
5.5. 任务完成率和对话长度的结果
在表1中,我们提供了与任务完成率和对话长度指标相关的结果。 我们使用了10种不同的用户模拟和系统策略对。 在我们之前的实验中,我们还实现了一个简单的seq2seq用户仿真模型,没有明确的对话状态跟踪,但由于结果不佳,我们从文件中省略了。
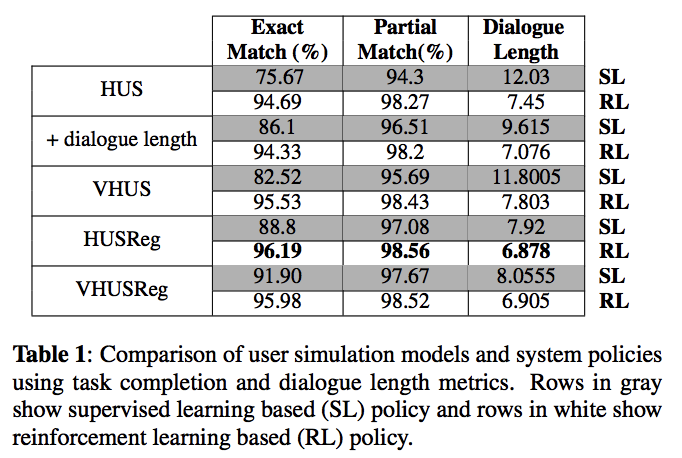
5.5.1. 评估对话策略
与SL策略相比,RL策略优于SL策略并生成明显更高的任务完成率。我们观察到在EM度量中差距大于PM度量。一个合理的解释是SL策略陷入局部最小值并且无法恢复某些槽位-值对。另一方面,RL策略能够成功地生成正确的槽位-值对。所有用户模拟器在RL策略下的每个对话的轮数也会大大减少。当我们降低用户模拟器的复杂性和有效性时(从下到上),RL和SL之间的差距会增大。 RL策略对EM和PM指标的性能不受不同用户模拟器的影响;但对于SL策略来说,当存在较弱的用户时,性能会显著下降。这些观察结果表明,即使回复更具随机性(如VHUS),RL对不同类型的用户也更加健壮。当我们从HUS中排除对话长度时,由于缺乏对较弱用户的鲁棒性,SL性能下降。请注意,使用用户模拟器的全自动方法获得的这些评估结果与[7]中提供的人类评估结果一致。
5.5.2. 评估用户模拟器
我们还使用相同的策略和指标来比较用户模拟器及其组件。当我们结合进对话长度时,HUS能够解决用户类型对对话长度和其他因素的影响,从而导致更成功和更短的对话。 VHUS产生更多样化和更随机的用户响应,这降低了SL策略的性能并增加了平均对话长度。虽然RL策略可以从这些更加不可预测的情况中恢复,但对话的平均轮次增加了0.7回合甚至更多。VHUSreg 根据实际用户与初始用户目标的差异,在每个回合中对用户响应进行惩罚,产生更成功的对话,这些对话也更短且更注重目标。 EM和PM增加的一个原因是目标正则化倾向于产生尽可能短的对话并有效地减轻诸如无限循环之类的策略的缺点。当我们用可变步骤增加HUSReg时,RL策略的性能不受影响,但SL的任务完成率增加。我们还观察到平均对话长度没有增加,这归因于目标正则化产生较短对话的逆效应。
5.6. 回复多样性结果
使用同一组模拟对话,在表2中,我们展示了与回复多样性度量相关的结果。 注意,熵和困惑度是在对话行为的层面上计算的,以衡量每种方法产生不同反应的能力,并且当行为转换为自然语言话语时,预期的指标结果会显着增加。
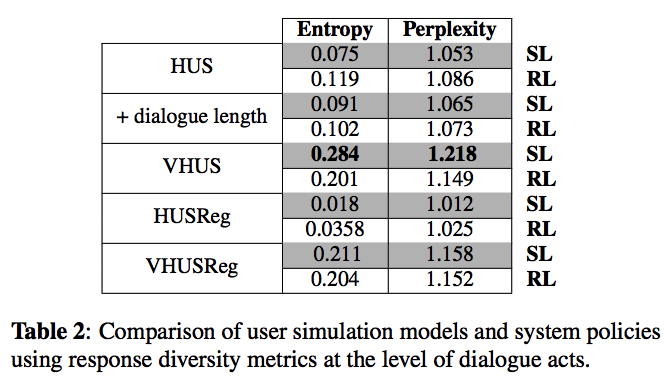
5.6.1. 评估对话策略
RL策略产生稍高的熵和困惑度分数,并且除了可变的模拟之外,在所有用户模拟上产生更丰富的对话。 我们认为引入用户反应的多样性与平均对话长度正相关; 因此,RL策略将尝试通过平衡对话轮次和总奖励来减少用户回复中的非常高的不确定性。 我们还观察到,相比于VHUS,当SL策略与VHUSReg交互时,用户回复的多样性会下降,而RL策略中则非常相似。 RL策略性能的这种相似性可以与我们上面的推理相关联; RL政策试图平衡对话长度和总奖励,这限制了用户回复的最大多样性。
5.6.2. 评估用户模拟器
VHUS 和 VHUSReg 在所有指标和系统策略上产生更高的多样性分数,这证实了我们的假设,即引入可变性步骤会增加用户回复的多样性。 VHUSReg 上的多样性得分小于SL策略中的 VHUS,这是所提出的目标正则化损失的结果,其控制了用户响应与初始目标的差异。 与其他用户模拟器相比,HUSReg 还生成更简洁的对话,具有最小的多样性分数和最小的对话长度。 当我们将对话长度纳入 HUS 时,我们观察到多样性得分没有变化,同时改善任务完成率和对话长度的表现。
5.7 使用真实的用户评估
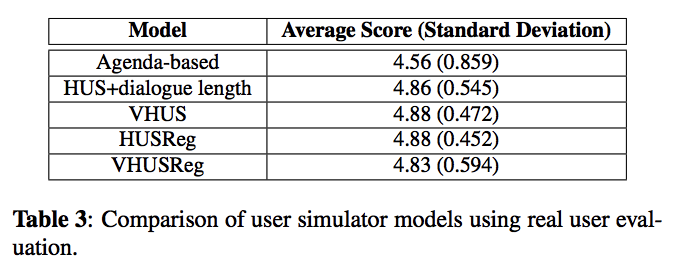
我们向众包提供了每个数据集的100个对话子集,供人工评估。 这些对话的所有轮次都通过基于模板的生成转换为自然语言,并且由3个众包人员以1到5的等级标注在对话的背景下该轮次的清晰度和适当性。 表3显示了回合制平均分数。 我们观察到所有用户仿真模型都会产生非常成功的轮次。我们还将用户仿真模型与手工制作的基于议程的用户仿真模型进行了比较[16]。 与基于议程的用户模拟相比,我们的模型具有更高的平均用户得分和更低的标准差。 对这种差异的一个特别解释是,基于议程的模拟可以产生偏离对话历史景的对话轮次。
6. 总结
我们研究了在面向任务的对话中对用户进行建模的问题,并提出了几种能够与不同系统策略成功交互的端到端模型体系结构。 通过我们的用户模拟器与最先进的系统策略之间的系统交互,我们为评估面向任务的对话提供了新的见解。 实验表明,RL策略更侧重于理解用户的隐藏意图,并且在用户回复的变化上更加鲁棒。 通过在 HUS 中加入可变性步骤,我们能够在模型中引入有意义的多样性。 我们引入了一种新的目标正则化方法,可有效降低平均对话长度,同时提高任务完成率。 最后,所提出的混合模型在产生多样化的回复和用户轮次的成功率之间取得了良好的平衡。
7. 参考文献
[1] Steve J. Young, “Probabilistic methods in spoken–dialogue systems,” Philosophical Transactions of the Royal Society of London A: Mathematical, Physical and Engineering Sciences, vol. 358, no. 1769, pp. 1389–1402, 2000.
[2] N. Gupta, G. Tur, D. Hakkani-Tur, S. Bangalore, G. Riccardi, ¨ and M. Rahim, “The AT&T spoken language understanding system,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, no. 1, pp. 213–222, 2006.
[3] Dan Bohus and Alexander I Rudnicky, “The ravenclaw dialog management framework: Architecture and systems,” Computer Speech & Language, vol. 23, no. 3, pp. 332–361, 2009.
[4] Tsung-Hsien Wen, Milica Gasic, Nikola Mrksic, Lina Maria Rojas-Barahona, Pei-Hao Su, Stefan Ultes, David Vandyke, and Steve J. Young, “A network-based end-to-end trainable task-oriented dialogue system,” CoRR, vol. abs/1604.04562, 2016.
[5] Tiancheng Zhao and Maxine Eskenazi, “Towards end-to-end learning for dialog state tracking and management using deep reinforcement learning,” in Proceedings of SigDial 2016, 2016.
[6] Xuesong Yang, Yun-Nung Chen, Dilek Hakkani-Tur, Paul Crook, Xiujun Li, Jianfeng Gao, and Li Deng, “End-to-end joint learning of natural language understanding and dialogue manager,” in Proceedings of IEEE ICASSP, 2017.
[7] Bing Liu, Gokhan Tur, Dilek Hakkani-Tur, Pararth Shah, and Larry Heck, “End-to-end optimization of task-oriented dialogue model with deep reinforcement learning,” in NIPS 2017 Workshop on Conversational AI, 2017.
[8] Layla El Asri, Jing He, and Kaheer Suleman, “A sequenceto-sequence model for user simulation in spoken dialogue systems,” CoRR, vol. abs/1607.00070, 2016.
[9] Baolin Peng, Xiujun Li, Lihong Li, Jianfeng Gao, Asli Celikyilmaz, Sungjin Lee, and Kam-Fai Wong, “Composite taskcompletion dialogue system via hierarchical deep reinforcement learning,” arxiv:1704.03084v2, 2017.
[10] Paul Crook and Alex Marin, “Sequence to sequence modeling for user simulation in dialog systems,” in Proceedings of the 18th Annual Conference of the International Speech Communication Association (INTERSPEECH 2017), 2017, pp. 1706– 1710.
[11] Iulian Vlad Serban, Alessandro Sordoni, Ryan Lowe, Laurent Charlin, Joelle Pineau, Aaron C. Courville, and Yoshua Bengio, “A hierarchical latent variable encoder-decoder model for generating dialogues,” CoRR, vol. abs/1605.06069, 2016.
[12] Alessandro Sordoni, Yoshua Bengio, Hossein Vahabi, Christina Lioma, Jakob Grue Simonsen, and Jian-Yun Nie, “A hierarchical recurrent encoder-decoder for generative contextaware query suggestion,” CoRR, vol. abs/1507.02221, 2015.
[13] Jiwei Li, Minh-Thang Luong, and Dan Jurafsky, “A hierarchical neural autoencoder for paragraphs and documents,” CoRR, vol. abs/1506.01057, 2015.
[14] D. P Kingma and M. Welling, “Auto-Encoding Variational Bayes,” ArXiv e-prints, Dec. 2013.
[15] O. Fabius and J. R. van Amersfoort, “Variational Recurrent Auto-Encoders,” ArXiv e-prints, Dec. 2014.
[16] Jost Schatzmann, Blaise Thomson, Karl Weilhammer, Hui Ye, and Steve Young, “Agenda-based user simulation for bootstrapping a POMDP dialogue system,” in Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion Volume, Short Papers, Rochester, New York, April 2007, pp. 149–152, Association for Computational Linguistics.
[17] Kallirroi Georgila, James Henderson, and Oliver Lemon, “Learning user simulations for information state update dialogue systems,” in INTERSPEECH, 2005.
[18] Kallirroi Georgila, James Henderson, and Oliver Lemon, “User simulation for spoken dialogue systems: learning and evaluation,” in INTERSPEECH, 2006.
[19] H. Cuayahuitl, S. Renals, O. Lemon, and H. Shimodaira, “Human-computer dialogue simulation using hidden markov models,” in IEEE Workshop on Automatic Speech Recognition and Understanding, 2005., Nov 2005, pp. 290–295.
[20] Florian Kreyssig, Inigo Casanueva, Pawel Budzianowski, and ˜ Milica Gasic, “Neural user simulation for corpus-based policy optimisation for spoken dialogue systems,” CoRR, vol. abs/1805.06966, 2018.
[21] Oriol Vinyals, Lukasz Kaiser, Terry Koo, Slav Petrov, Ilya Sutskever, and Geoffrey E. Hinton, “Grammar as a foreign language,” CoRR, vol. abs/1412.7449, 2014.
[22] KyungHyun Cho, Bart van Merrienboer, Dzmitry Bahdanau, and Yoshua Bengio, “On the properties of neural machine translation: Encoder-decoder approaches,” CoRR, vol. abs/1409.1259, 2014.
[23] Olivier Pietquin and Helen Hastie, “A survey on metrics for the evaluation of user simulations,” The knowledge engineering review, vol. 28, no. 1, pp. 59–73, 2013.
[24] Ronald J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement learning,” Machine Learning, vol. 8, no. 3, pp. 229–256, May 1992.
[25] Pararth Shah, Dilek Hakkani-Tur, Bing Liu, and Gokhan Tur, “Bootstrapping a neural conversational agent with dialogue self-play, crowdsourcing and on-line reinforcement learning,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 3 (Industry Papers). 2018, pp. 41–51, Association for Computational Linguistics.
[26] Diederik P. Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” CoRR, vol. abs/1412.6980, 2014.